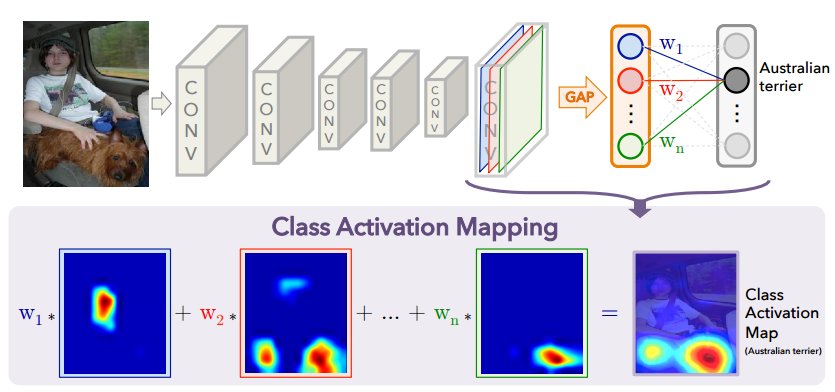
In this work, we revisit the global average pooling layer and shed light on how it explicitly enables the convolutional neural network to have remarkable localization ability despite being trained on image-level labels. While this technique was previously proposed as a means for regularizing training, we find that it actually builds a generic localizable deep representation that can be applied to a variety of tasks. Despite the apparent simplicity of global average pooling, we are able to achieve 37.1% top-5 error for object localization on ILSVRC 2014, which is remarkably close to the 34.2% top-5 error achieved by a fully supervised CNN approach. We demonstrate that our network is able to localize the discriminative image regions on a variety of tasks despite not being trained for them.
What the CNN is looking and how it shifts the attention in the video
Here we apply the class activation mapping to a video, to visualize what the CNN is looking and how CNN shifts its attention over time. The word on top-left is the top-1 predicted object label, the heatmap is the class activation map, highlighting the importance of the image region to the prediction. The source video is from and credited to Kyle McDonald
Class Activation Mapping and Class-specific Saliency Map
We propose a technique for generating class activation maps using the global average pooling (GAP) in CNNs. A class activation map for a particular category indicates the discriminative image regions used by the CNN to identify that category. The procedure for generating these maps is illustrated as follows:
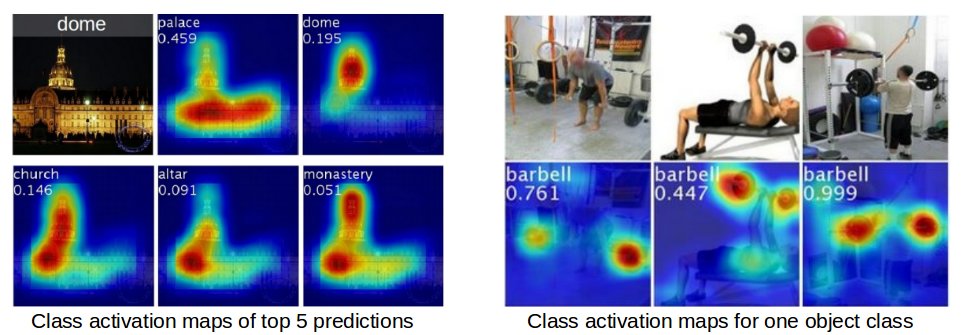
Class activation maps could be used to intepret the prediction decision made by the CNN. The left image below shows the class activation map of top 5 predictions respectively, you can see that the CNN is triggered by different semantic regions of the image for different predictions. The right image below shows the CNN learns to localize the common visual patterns for the same object class.
Furthermore, the deep features from our networks could be used for generic localization, with newly trained SVM's weights to generate the class activation map, then you could get class-specific saliency map for free. Check the paper for the detail or check the supplementary materials for more visualization.
Reference
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning Deep Features for Discriminative Localization. CVPR'16 (arXiv:1512.04150, 2015).
@article{zhou2015cnnlocalization,
title={{Learning Deep Features for Discriminative Localization.}},
author={Zhou, B. and Khosla, A. and Lapedriza. A. and Oliva, A. and Torralba, A.},
journal={CVPR},
year={2016}
}
Acknowledgement: This work was supported by NSF grant IIS-1524817, and by a Google faculty research award to A.T.